“95% of Gen AI pilots Fail.”
I’m sure you’ve heard this on a podcast or some version used as a lead-in to another LinkedIn trash post and perhaps you went so far as to internalize this stat as a reason for challenging investment in AI in your org. This would be misguided.
LinkedIn’s flavor-of-the-month factoid came to us from the NANDA team at MIT. Project NANDA (Networked Agents and Decentralized AI) is an MIT Media Lab initiative to build the infrastructure that allows AI agents to discover, interact, collaborate, and transact securely at scale. In addition to the assumed technical capabilities of the team attributable to the MIT halo the NANDA project also deserves kudos for making a clickbait factoid bold enough to get the world to care about the performance of corporate technology pilots.
I took the time to read the 26 page report over the Labor Day weekend and here’s my TL;DR:
This is an ok report with a good, albeit highly massaged click bait hook.
I took some time to process my gripes with the research and presentation format, some solid advice that whitepaper puts forward (including some tried-and-true suggestions well-developed in the last decade of general digital transformation literature) and a pretty succinct 4 point suggestion list that most business leaders should internalize (stealing a move from NANDA, I’ve inconveniently buried this beneath a lot of my other less succinct and less powerful ideas).
Where the report falls short:
1. The report is derived from a relatively small sample size of interviews and survey responses
While I can’t think up a better experimental design than “Let’s poll a bunch of business leaders” myself, it should be mentioned that the report is based on a relatively small data set. In the Appendix, the authors indicate that the findings are based on results from 52 structured interviews and survey responses from 153 leaders of “enterprise” organizations (1000 or more employees). This is hardly a cross-section of global business leaders, and I suspect there may be some Negativity Bias amongst participants a la Yelp. If you were a business leader sitting on a really successful AI deployment would you spill the tea to your competitors? If you were a business leader sour for sponsoring a project that went belly-up, would you be more likely to leave a 1-star review? My suspicion is “no” to the former and “yes” to the latter which could go a long way to explaining the eye-popping 95% figure.
2. Are business leaders really the best people to focus on?
I didn’t grasp the relative seniority level of the “business leaders” targeted for this report, but my impression is the authors want us to assume C-suite executives. Let’s go along with this assumption. In my experience selling last-gen SaaS and supporting strategic roll outs of AI and Data Science, the person highest on the org chart is rarely the right person to evaluate the efficacy of a new tool. C-suite leaders distribute budget based on the conviction of managers who are more in the weeds. Then they claim victory when things work. I’d be more swayed if the report included a project-by-project analysis that focuses on the manager-level talent that are staking their credibility on these roll-outs. They’ll be able to give us reports on qualified successes, learnings that will impact future deployments, and perhaps a better understanding on when the success will be felt by the higher-ups.
3. The report defines success narrowly
The benchmark for success in the report is pilots that make a tangible impact on a P+L. How many projects are effectively scrutinized to this degree? The authors do admit that measuring business impact is really tricky and for this reason many pilots are being approved in Sales and Marketing where easy-to-measure metrics abound. By this measure, a pilot that saves an individual worker 10hrs per week would be a failure. While it is easy to see how giving someone back 10hrs to do more rewarding work or to do other work could make a huge difference for a business unit it would not hit the bottom line (unless you scaled back that worker’s pay for the 10hrs, a fairly unlikely business practice. If it saved 40hrs…. Maybe you’d lay them off). In either instance, this narrow definition and an undisciplined reporting on how long it has been since pilots have been deployed is muddying the business take away. Is this a valuable tool that has not yet impacted the P+L? Will it impact the P+L in coming cycles if layoffs do materialize? Answering these questions would weaken the click-bait assertions.
4. Too much focus on text-generating AI
The below exhibit from the report categorizes the projects that received budget approval from the polled business leaders:
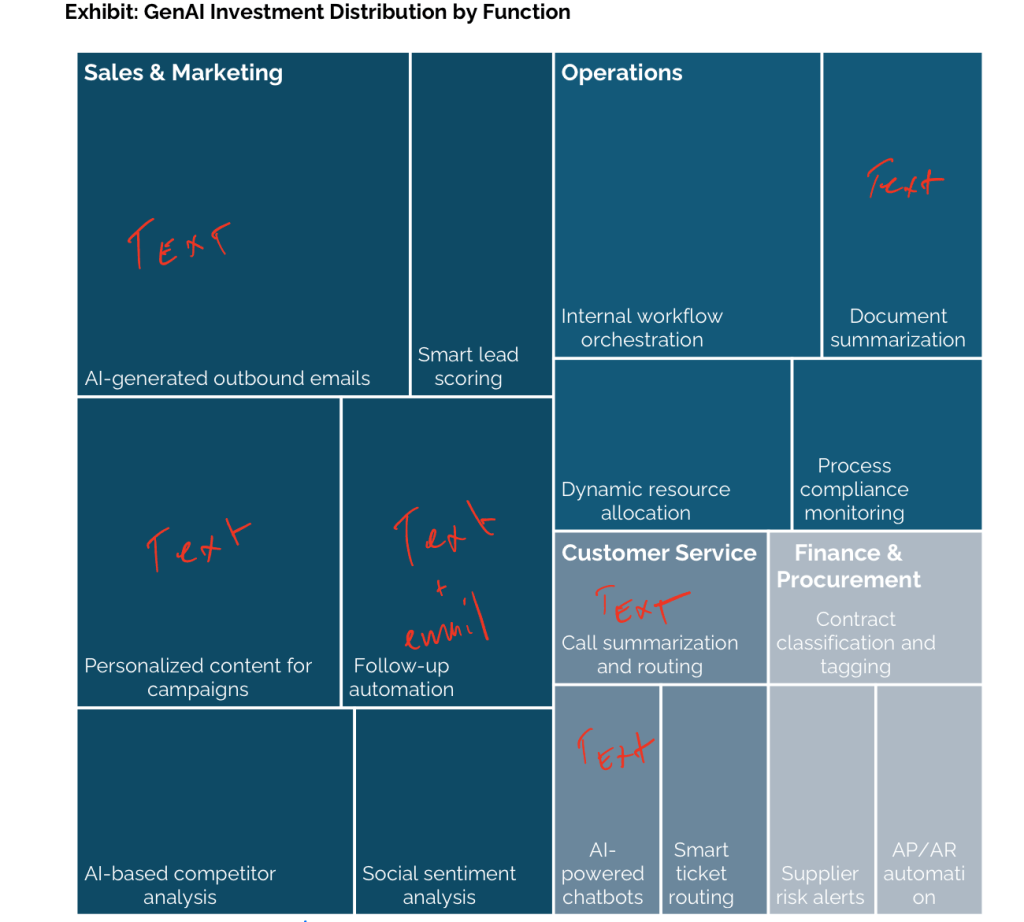
I lazily scratched out squares that are basically text-based tasks. The authors want you to take away the idea that there’s an over-abundance of Sales and Marketing pilots approved. My take away was closely tied to the point in 2. Above: execs probably aren’t the right people to look to for AI improvements. The first time you used ChatGPT, you too were probably amazed by the tool’s ability to generate lines of text effortlessly. “Hey I could use this to write emails!” or “This could write my marketing copy!” are probably the first 2 ideas that come across within 3 seconds of your first response. This low-hanging fruit approach to Gen AI pilots points to approvals by teams that haven’t done their homework to really think about AI’s potential for an organization. This was the best read-between-the-lines evidence of a poor survey population.
As an aside: writing sales and marketing emails with AI is stupid. Everyone is doing it and they all suck. If you want to make a sale or engage your audience, do the work that makes it sound human and worth the readers’ time.
Griping over! (mostly). There are some solid ideas that readers should take away from this report. Despite the algorithm’s antipathy for balanced opinions, we’ll give the NANDA reports it proper respect as well:
1. Gen AI is different than past tools: your workers are already using it
One of the biggest obstacles to Enterprise AI adoption is the tools we’re building at work aren’t as good as the ones we’re using at home. Many users have incorporated ChatGPT and CoPilot into our day-to-day workflows in and outside of the work. When workers are presented with AI solutions, they anticipate flexible chat-based interfaces that are able to be prompted and re-prompted to deliver increasingly better outputs. If your pilot AI product is built on pre-set prompts, your users are bound to be underwhelmed. In these cases it’s likely the users will boot up their personal subscription services and go about solving problems in the manner they’re already accustomed to, a problem the paper dubs “AI shadow usage.” A primary impact: your pilot usage will plummet. A potential secondary impact: proprietary data and information gets leaked to LLMs as workers dump .csv files into their favorite chat (with history and memory turned “on”) for analysis.
2. Context, Memory, and Adaptation are key hurdles
When performing complex actions with AI, good outputs take a fair amount of coaxing. Tuning your model for context usually requires uploading several documents then include some significant expository detail to catch the model up to what you’re trying to do. Doing this right takes some time and expertise, and unfortunately, your model will probably forget this work next time you sit down to work on a similar problem. This is AI’s memory problem. What is probably even more frustrating than model forgetfulness is adverse adaptations (ie: hallucinations). When the work gets hard, the models get lazy. This can result in wrong answers or attempts that speed past some key context. When this starts happening it’s time to start a new chat as the model begins to adapt away from your core need. New solutions from top-tier LLMs are starting to incorporate memory in new models that will hopefully start solving these problems across consumer contexts. If you’re building your own AI solutions, however, it’s just a new feature to accomplish to please users who are getting taught what good AI is by OpenAI.
3. Start small and distribute ownership
The report makes a good point that’s more of a reminder for any business leaders that have worked to incorporate agile workflows and mindsets: Top-down projects tend to fail. The report references org-wide AI projects that we can infer followed a waterfall-style roll out. These big projects are challenged to serve enough users while providing any individual user with enough value to materially improve their day-to-day. The only top-down AI rollout with a strong likelihood of success I can conceive of would be activating a tool like Microsoft CoPilot. After you taken the time to put Enterprise-safe GenAI in your users’ hands it’s wise to heed the report:
“The standout performers are not those building general-purpose tools, but those embedding themselves inside workflows, adapting to context, and scaling from narrow but high-value footholds.”
The implication here is clear: empower workers close to the problems to experiment with solutions. The most advanced AI solutions in 2025 fall short because they lack context. Your workers have deep context that your leaders probably don’t. Starting with small use cases managed by workers with deep problem context is a winning formula. Success is likely to compound from there.
4. Buy > Build; Look for vendors who offer services along with their products
The “Buy vs Build” question deserves a fresh coat of paint post-GenAI. On one hand, “Build” is considerably easier than years past. Tech-limited workers can leverage tools like Cursor to spin up applications, algorithms, and more to solve problems that were previously out of reach. Yet from an Enterprise context, NANDA’s recommendation is pretty clear: Buy, from the right vendors. The paper mentions that pilots offered by companies that offer a high-degree of customization, service, and support are correlated with a higher rate of success. Retaining a team of experts who can quickly parachute in to improve the product or tweak its implementation means organizations do not need to pay to have this talent on-staff. These types of organizations are also more likely to offer next-gen business models like results-based fee structures that ensure companies are only paying when value is created.
In general, this is sound advice. Yet there are 2 notes I’d like to include:
- Some of NANDA’s members and co-authors of the paper are proprietors of small, agentic-focused companies who likely offer this exact type of service. Wise readers should ingest this and be wary that we may be indexing on some embedded SponCon.
- Small companies and early stage startups are the most likely organizations sufficiently motivated to offer this level of service. In some cases, servicing accounts to this degree comes at the expense of improved products over time. Thus, hiring a company for today’s service could come at the expense of tomorrow’s product. The point of rolling out AI is to build around scalable solutions. Companies that are effectively modern-day Mechanical Turks are not scalable.
5. Back-Office Automation is a source of sustained ROI
Go past GenAI for email writing. Hire agents to do your boring work. Again, it’s important to call out the potential embedded SponCon situation here, but this is sound advice. GenAI plays a role in these systems (interpreting semantic commands into tasks executable by a machine) but the core value is accreted when companies can replace BPO service providers and brittle automation workflows managed in last-gen SaaS platforms. Solutions that eliminate back-office drudgery may not be celebrated the way new revenue generation is, but its likely a sustained business advantage that will enable your team to win more in the future for cheaper.
Now that you’ve trudged through my gripes, musings, and occasional kudos I’ll leave you with NANDA’s best stuff. Here are the overarching 4 suggestions from the paper that apply to most AI pilots:
- Demand deep customization aligned to internal processes and data
- Benchmark tools on operational outcomes, not model benchmarks
- Partner through early-stage failures, treating deployment as co-evolution
- Source AI initiatives from frontline managers, not central labs
In sum, if you didn’t read past the click bait (or my long winded reaction to the clickbait) take these 4 simple points with you. NANDA’s paper may not be as effective as its tag line, but there is value here. Best of luck to all of you on your pilots.

Leave a comment